Assuming we and our teams bought into domain-driven design, the next question is, how do we interact between modules? Giving access to domain entities sounds like a great idea, but it carries consequences.
There is a good argument to be had for exposing entities. After all, we spend a lot of effort ensuring our code expresses our domain well. On top of that, we ensure data can’t get into an invalid state, and trying to do so returns a descriptive error. Why would we forfeit it?
When a module uses another module’s domain, it depends on it. Consequences touch both modules. Changes to dependency could require lots of work to modules that use it, or result in breakage. On the other side, the dependency itself can’t change as freely. When a domain is used directly, it becomes a silent interface.
When I use “module” here, I mean part of software that we want to keep separate. It could be a separate service, living in a different repository, or a separate package, living in a neighboring folder.
When the exposed domain changes
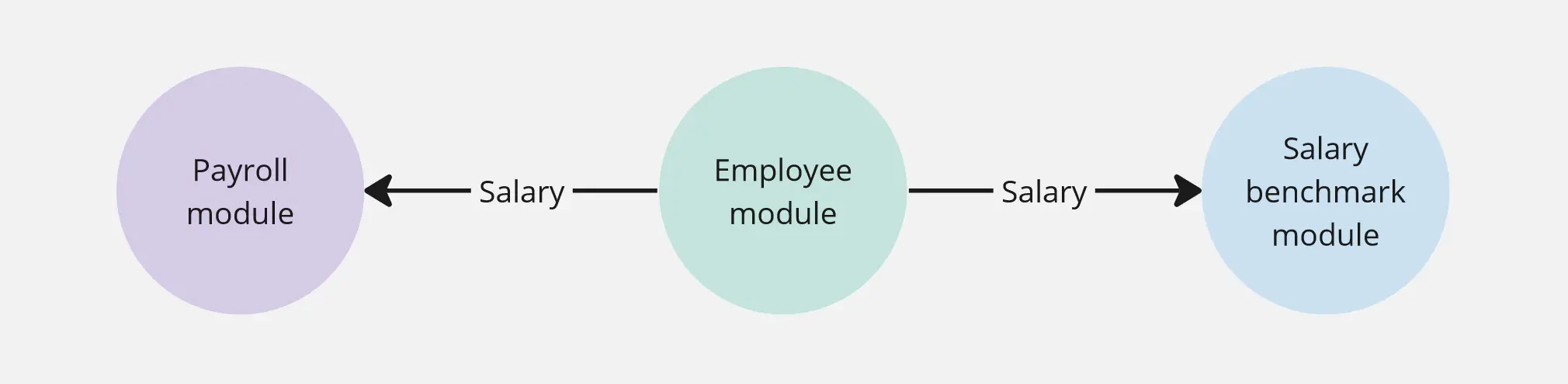
Take a look at this example. Both payroll and benchmarking modules require data from employees. The former calculates monthly pay, and the latter measures how competitive a pay is. (Very simplified example, but it will do for this article.)
Let’s pause here for a second. “Salary” is used in all three modules, but it means something slightly different for each module. It is a common pitfall to treat property with the same name in different modules as the same concept. We should keep these separate, as they will change for different reasons. We’re not violating DRY (Do not Repeat Yourself) rule here.
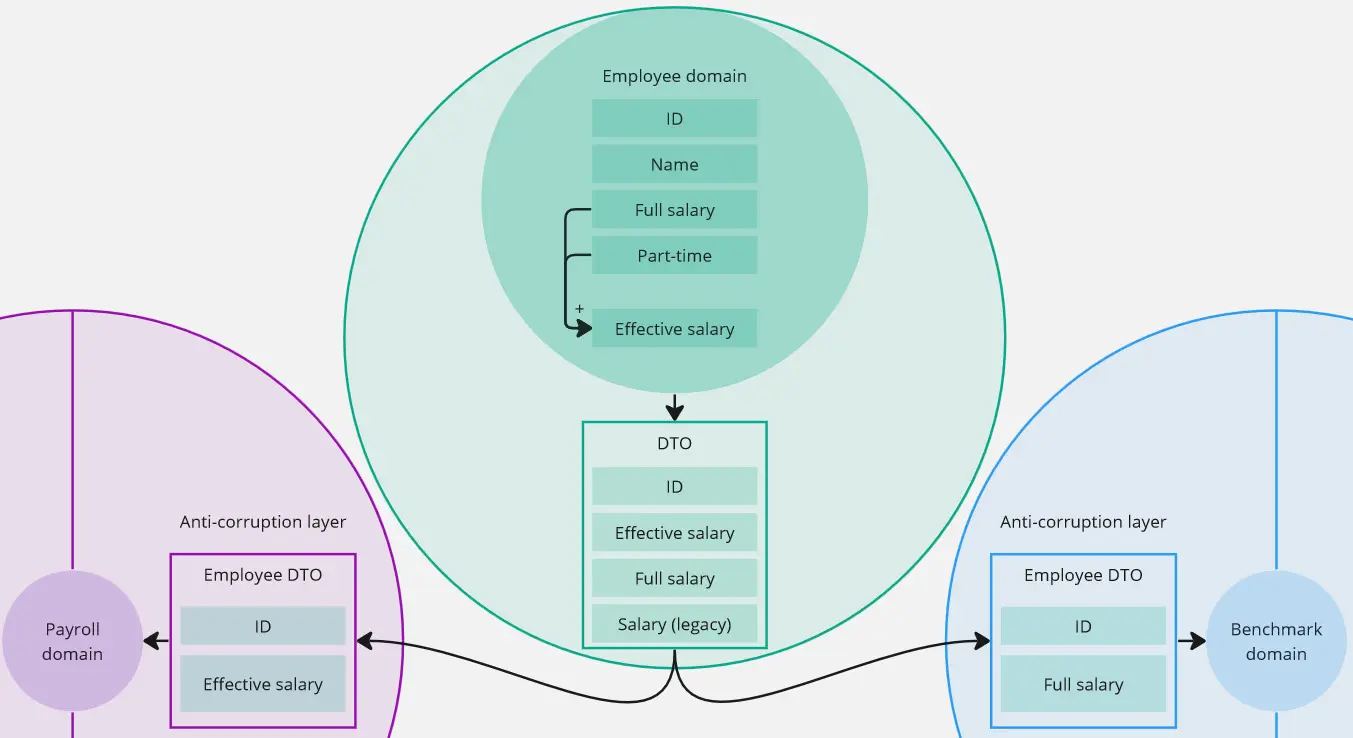
Continuing with our example, let’s imagine our software evolves. Users might want a new feature: part-time employment. This change will require adjustments in all three modules. The payroll module would like to know the effective salary - if someone is working half-time, it would like the received salary to be already adjusted. The benchmarking module, on the other hand, doesn’t care about this change - it wants a full salary.
Could we predict this? Maybe. In my experience, unfounded predictions lead to over-engineered solutions. We solve a problem that never emerged or implement it incorrectly (because we know very little). We have two options: keep it simple and let the issue hit us, or use patterns that limit the impact.
Anti-corruption layer
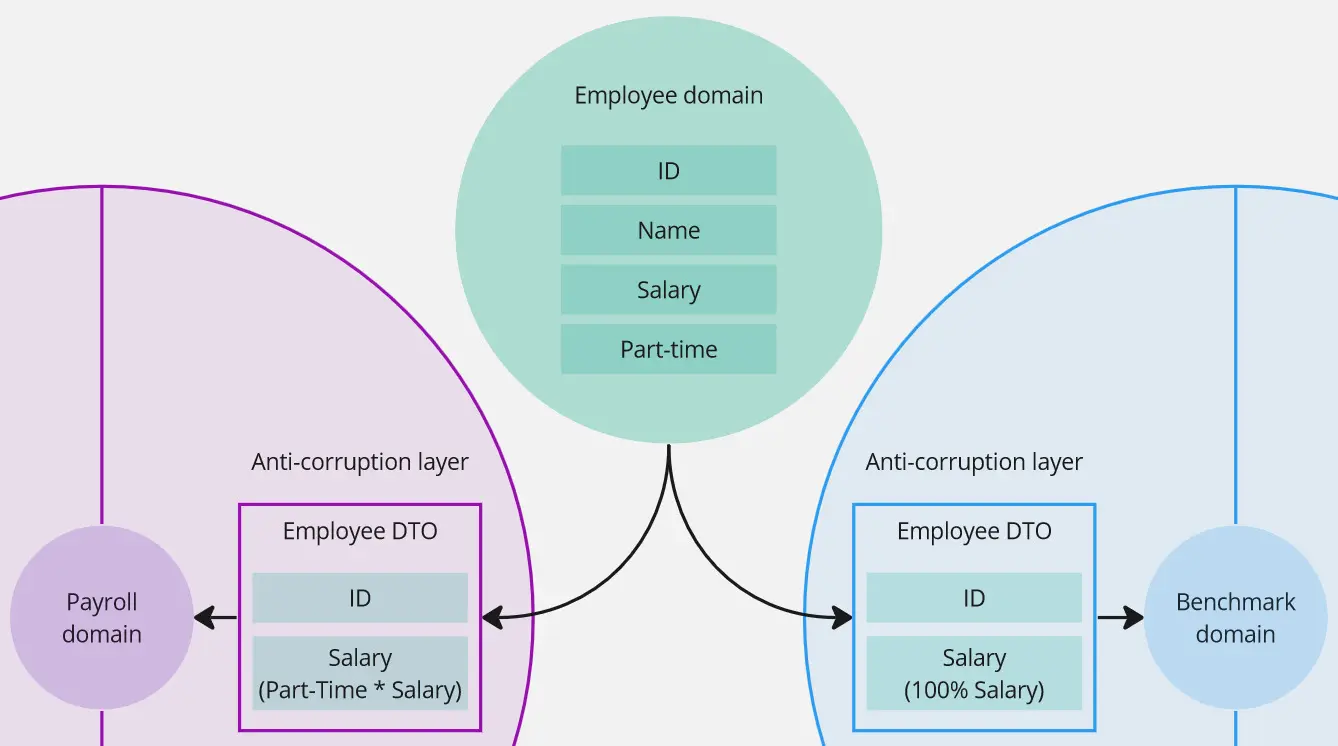
The aim of the first pattern is to protect the module from external changes. It doesn’t remove the necessity for changes but usually limits them to one place.
Is that “Duplication!” alarm in our heads? Good. Adding another layer has its costs. If we want to add a new property, this is yet another place we have to introduce a change. However, here, we seem to have a good reason - these types are not the same. Employee module probably has different concerns, like ensuring salary doesn’t go below minimum wage, or doesn’t start before hired-on date. Within the payroll module, it’s just a number, which shouldn’t be negative. (Of course, there could be an argument, that payroll should also care about minimum wage. Playing with modules’ responsibilities will alter the pros and cons and, ultimately, our decision. Don’t forget to talk to the domain expert.)
Dependency rejection
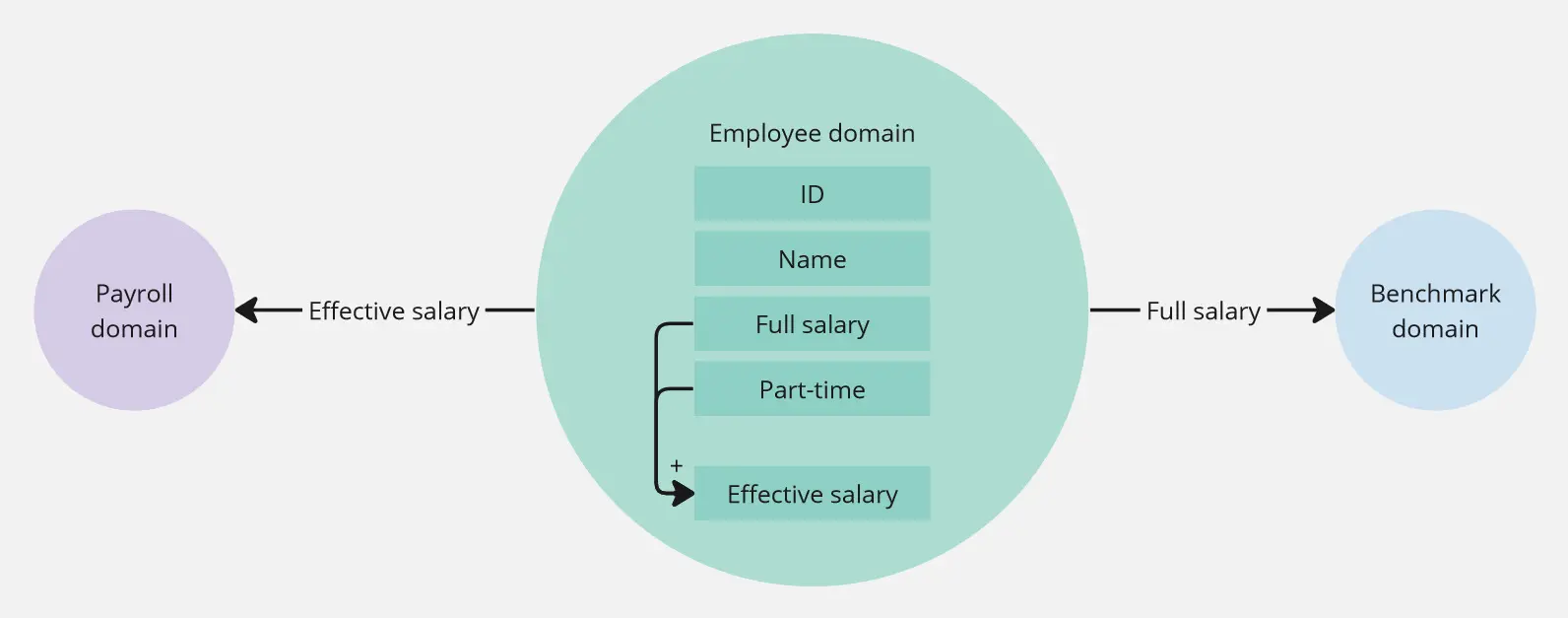
The second pattern, dependency rejection, deals with this problem differently. We can reject knowing about the details of another module. Instead of gathering multiple properties and computing what we need ourselves, we request a module we depend on to do computation and provide us with the result. The aim is to slim down our dependencies. This approach is helpful in two scenarios. The first one comes into play, when we take in multiple data points, just so that we can calculate simple object(s). The second one is a statement of importance - when we deem one module more precious, allowing us to reject some responsibilities. A good reason for this would, be to keep the core of our money-maker more straightforward, thus easier to maintain and grow.
Our example could be argued for both cases. I’m going to lean more into the first one, as I deem it more valuable - payroll rejects understanding the complexities behind effective salary. After all, it might take a couple of sub-modules to come up with that number (spoiler, it does), and we don’t want to touch payroll every time one of them changes.
Properly used, this pattern has advantages for both modules. The module that rejects dependency will make itself simpler. The benefit for the rejected module is more freedom to change - as long as the exposed data point doesn’t break the agreed-upon interface.
When we use the anti-corruption layer, we still have to change our module, whenever the source of data changes. The dependency rejection pattern protects us from this entirely. However, it pushes additional responsibility to the module it depends on.
The main danger comes from the tendency for one part of the application to gather a lot of complexity. The more logic a module has, the more tempting it is to stack even more, as we have direct access to a lot of data points.
Protecting domain from external usage
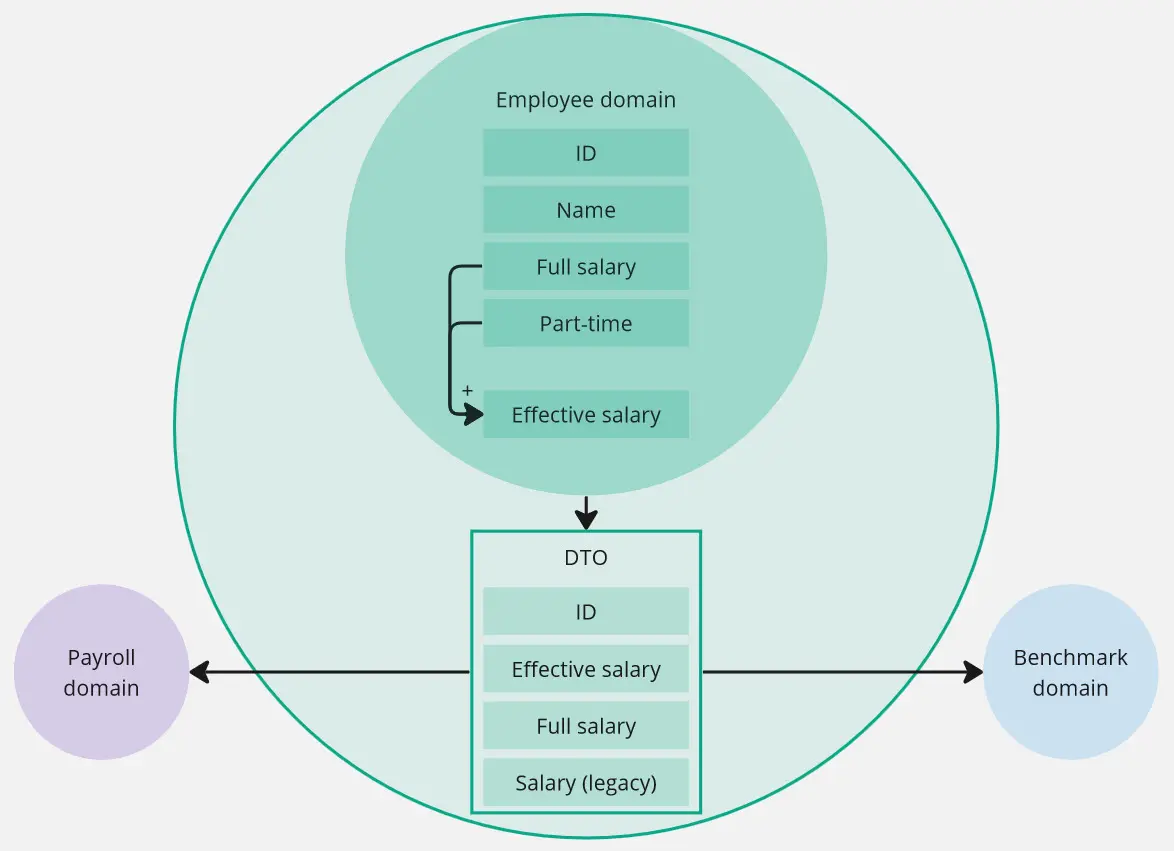
Ideally, other layers should change to fit the domain. When a domain is used directly, it isn’t that simple. In practice, changing the domain’s contract, in a non-backward-compatible way, will greet us with a compilation (or worse, runtime) error. This will influence the domain, or at least slow it down.
One way to combat it is to wrap the domain in an extra layer. It will act as a buffer, shifting the responsibility of being an interface out of the domain. This is often a product (deliberate or not) of microservice-oriented architecture. With some consideration, we can achieve the same effect for domains that live in the same repository or binary.
The hard part is to determine when adding an extra coating gives us value. Done haphazardly, it increases complexity and introduces unnecessary duplication. Before we start, the boundaries of our module have to be well-defined. Moving the interface responsibility out of the domain is worth considering when we expect a lot of downstream usages, common breaking changes, or supporting old versions.
Taking a step back

Combining everything together definitely can’t be summarized as “simple”. Each new feature requires more effort and touches more files. We should have a solid reason for each abstraction we add.
Let’s go back to the very beginning when we wanted to split “salary” into “effective salary” and “full salary”. If we haven’t added any of this abstraction beforehand, there is no way to avoid breaking changes. Now, it is time to pay our debt. We can use the pain of change to decide which patterns to use.
Do we want the employee module to move faster, without breaking things and waiting for others to catch up? Dependency rejection and not exposing the domain will help.
Are we afraid of more breaking changes in payroll or salary benchmarking? The anti-corruption layer will reduce it.